Hadoop Developer Resume Guide
Hadoop developers are responsible for building and managing big data solutions using the Hadoop platform. They work with clients to understand their business needs and create custom Hadoop-based solutions. In addition, they also troubleshoot and optimize Hadoop systems as needed.
You’re a skilled Hadoop developer. However, potential employers won’t know about your skills unless you write a resume highlighting your experience and qualifications.
This guide will walk you through the entire process of creating a top-notch Hadoop developer resume. We first show you a complete example and then break down what each resume section should look like.

Table of Contents
The guide is divided into sections for your convenience. You can read it from beginning to end or use the table of contents below to jump to a specific part.
Hadoop Developer Resume Sample
Eusebio Blick
Hadoop Developer
eusebio.x.blick@gmail.com
984-975-1467
linkedin.com/in/eusebio-blick
Summary
Well-rounded Hadoop developer with 4+ years of experience in big data solutions and MapReduce programming. Proven ability to work on Hadoop clusters of up to 100 nodes and develop efficient code to process large amounts of data. Experienced in Hive, Pig, Flume, Sqoop, and other Hadoop ecosystem components. Committed to continual learning and keeping up-to-date with the latest technologies and trends.
Experience
Hadoop Developer, Company ABC
Lexington, Jan 2018 – Present
- Structured and processed big data sets using Hadoop, HDFS and MapReduce framework to support business analytics.
- Advised clients on the best way to utilize Hadoop for their specific needs and use cases; helped them save an average of $5,000 per month in hardware and software costs.
- Assessed client’s current big data infrastructure and provided recommendations on how to improve performance by 30%.
- Streamlined the process of collecting, storing and analyzing big data by implementing a Hadoop-based solution; reduced processing time from 3 days to 12 hours.
- Independently designed, developed and tested new Hadoop applications according to project specifications; delivered projects on time and under budget 100% of the time.
Hadoop Developer, Company XYZ
New York City, Mar 2012 – Dec 2017
- Spearheaded the development of Hadoop-based solutions for big data processing and analysis, including creating custom MapReduce programs to process large datasets.
- Achieved a 20% increase in performance and efficiency in data processing by optimizing existing Hadoop cluster configurations.
- Resourcefully utilized open source libraries and tools to develop innovative solutions for complex big data problems.
- Reduced the time needed for data processing tasks by 30% on average through effective use of Hadoop resources.
- Optimized Hadoop cluster utilization levels through careful planning and management of jobs and workloads.
Skills
- Apache Hadoop
- Apache Spark
- Apache Hive
- Apache HBase
- Apache Kafka
- Apache Flume
- Apache Sqoop
- Apache Oozie
- Apache Mahout
Education
Bachelor of Science in Computer Science
Educational Institution XYZ
Nov 2011
Certifications
Hadoop Developer Certification
Cloudera
May 2017
1. Summary / Objective
Your resume summary is like a trailer for the rest of your resume – it should give the employer an overview of your skills and experience as a Hadoop developer.
Some points you may want to include are your proficiency in programming languages, big data platforms, and frameworks relevant to Hadoop development. You could also mention any awards or certifications you have related to Hadoop development, as well as any significant projects you have worked on in the past.
Below are some resume summary examples:
Dependable Hadoop developer with 4+ years of experience working in big data environments. Proven ability to develop scalable and efficient Hadoop solutions for a variety of clients. Seeking to leverage expertise in HDFS, MapReduce, Hive, and Pig to support the big data needs of ABC company. At XYZ Inc., increased client satisfaction by 27% due to more efficient use of Hadoop clusters.
Determined Hadoop developer with 3 years of experience in MapReduce and HDFS. Implemented Hadoop-based solutions that increased data processing speed by 35%. At XYZ, utilized Hadoop to process 10 TB of raw data per day, reducing the time it took for analysts to gain insights from the data by 50%.
Talented Hadoop developer with experience in the analysis, design, and implementation of Hadoop solutions for a variety of clients. Skilled in developing MapReduce programs to process large-scale data sets using Java and Python. Seeking to leverage my skills and experience as a Hadoop developer at ABC Corporation where I can continue to learn and grow while making meaningful contributions to big data projects.
Hard-working Hadoop developer with 3 years of experience in big data analysis and management. Proven ability to develop high-quality Hadoop applications that are scalable, reliable, and fault-tolerant. Experienced in using various open source Hadoop ecosystem components such as Pig, Hive, Sqoop, Flume, Oozie, and MapReduce. Seeking to leverage my skills and knowledge to help ABC achieve its big data goals.
Amicable Hadoop developer with 3+ years of experience working on big data solutions. Skilled in developing MapReduce programs, configuring Hbase, and HiveQL. Received the “Best Team Player” award for collaborating with 15 other developers to create a successful e-commerce platform that processed 500TB of data per day.
Diligent big data engineer with over 4 years of experience working with Hadoop, MapReduce, Hive, and Pig. Experienced in developing big data solutions for a variety of clients across different industry sectors. At XYZ Inc., implemented a Hadoop-based solution that resulted in a 50% reduction in processing time for client’s insurance claims data.
Passionate Hadoop developer with 5+ years of experience in big data processing, analysis, and management. Seeking to leverage skills in MapReduce, Hive, and Spark to help ABC Company increase efficiency in data-intensive operations. At XYZ Inc., led the development of a Hadoop-based system that processed 2 PB of data for the company’s annual report.
Driven Hadoop developer with 3 years of experience in big data solutions and a strong interest in data science. At XYZ, used Hadoop to process large amounts of clickstream data per day and created several MapReduce jobs to extract valuable insights from the data. Wrote an article on “Getting Started with Hadoop” that was read by over 100,000 people.
Proficient Hadoop developer with 4+ years of experience in big data technologies. Proven ability to develop high-performance and scalable solutions for a variety of business needs. Seeking to use expertise in Hadoop, Hive, and MapReduce to contribute to the success of ABC’s big data initiatives. At previous companies, increased performance by 15% and reduced costs by 10%.
2. Experience / Employment
For the experience section, you’ll want to provide details on your employment history. This should be written in reverse chronological order, so that your most recent role is listed at the top.
When writing about what you did in each role, it’s best to stick to bullet points. This will make it easier for the reader to take in the information quickly. When detailing what you did, be sure to include concrete examples and quantifiable results whenever possible.
For example, instead of saying “Managed Hadoop cluster,” you could say “Installed, configured, and maintained a 20-node Hadoop cluster which processed 500GB of data per day.”
To write effective bullet points, begin with a strong verb or adverb. Industry specific verbs to use are:
- Developed
- Implemented
- Configured
- Administered
- Monitored
- Tuned
- Tested
- Debugged
- Documented
- Supported
- Upgraded
- Maintained
- Created
- Analyzed
- Investigated
Other general verbs you can use are:
- Achieved
- Advised
- Assessed
- Compiled
- Coordinated
- Demonstrated
- Expedited
- Facilitated
- Formulated
- Improved
- Introduced
- Mentored
- Optimized
- Participated
- Prepared
- Presented
- Reduced
- Reorganized
- Represented
- Revised
- Spearheaded
- Streamlined
- Structured
- Utilized
Below are some example bullet points:
- Actively participated in all aspects of the software development cycle, from requirements gathering to coding to testing and deployment.
- Represented the company at Hadoop user group meetings and meetups, sharing best practices with other developers and promoting our products/services.
- Debugged production issues related to Hadoop installations on a daily basis, often working directly with customers to resolve their problems quickly and efficiently.
- Created new MapReduce jobs to process customer data according to specific business needs; utilized HiveQL queries for data analysis when necessary.
- Utilized a wide variety of open source Hadoop-related projects (such as Pig, Sqoop, Flume) in order to build robust & scalable big data solutions for our clients.
- Efficiently processed large data sets using Hadoop MapReduce and Spark, reducing processing time by 70%.
- Revised existing Hadoop jobs to improve performance and optimize resource usage; achieved a 30% reduction in job execution time.
- Documented all aspects of the Hadoop development process, from initial requirements gathering to final testing and deployment; created user manuals for end users.
- Coordinated with other teams (such as Data Warehouse and Business Intelligence) to ensure that their needs were met during the Hadoop development process.
- Formulated new ideas for improving the efficiency of the Hadoop platform; developed & implemented new methods for data partitioning & clustering which improved query response times by 40%.
- Mentored a team of 4 junior developers in Hadoop and MapReduce programming, resulting in a 15% increase in productivity.
- Improved the performance of several Hadoop clusters by tuning parameters and configurations.
- Proficiently used Pig, Hive, Sqoop and Flume to process and analyze large data sets.
- Configured Hadoop security settings to enforce authentication and authorization policies.
- Wrote custom MapReduce programs to solve specific business problems.
- Reliably maintained and updated Hadoop Distributed File System (HDFS) across a multi-node cluster, ensuring smooth data processing and retrieval for over 500 users.
- Facilitated the creation of MapReduce jobs to process large amounts of data according to specified criteria, reducing job completion time by 20% on average.
- Supported end users in accessing HDFS data using HiveQL and Pig Latin, providing training and troubleshooting assistance as needed.
- Prepared detailed documentation on HDFS architecture, functionality and usage procedures for other IT staff members.
- Monitored HDFS performance metrics on an ongoing basis, taking corrective action as necessary to maintain optimal system performance levels.
- Administered a Hadoop cluster of 100 nodes, processing 2 PB of data per day.
- Upgraded the Hadoop version from 2.x to 3.x, which increased the performance by 30%.
- Compiled daily reports on the status of the Hadoop cluster and identified potential issues.
- Expedited the process of data ingestion into HDFS by developing a custom tool.
- Accurately processed customer data according to GDPR regulations.
- Introduced Hadoop to the company, and implemented it across all departments for data analysis.
- Analyzed complex datasets using Hadoop, and tested various scenarios for performance optimization.
- Meticulously documented all procedures related to Hadoop deployment and usage.
- Trained other employees on how to use Hadoop for data analysis tasks.
- Monitored the progress of data analysis projects and provided timely reports to management.
- Demonstrated excellent ability to develop Hadoop applications, consistently meeting deadlines and requirements.
- Developed a number of successful Hadoop projects, including a data warehouse for a major retailer which resulted in $3 million in savings.
- Reorganized company’s entire data processing infrastructure onto the Hadoop platform, reducing processing time by 80%.
- Participated in the development of Hadoop-based solutions for some of the world’s largest companies, such as Facebook and Yahoo!.
- Monitored and maintained Hadoop Distributed File System (HDFS), ensuring that data was consistently available and accessible to users.
- Confidently resolved complex issues with the HDFS, often being commended by colleagues for my in-depth understanding of the system.
- Presented findings from investigations into various aspects of the HDFS at monthly team meetings, helping to improve performance and stability company-wide.
- Investigated and identified potential improvements to the HDFS, leading to increased efficiency and productivity for the entire organization.
3. Skills
The skills section is one of the most important parts of a Hadoop developer’s resume. This is where you will list all of the specific skills and qualifications that are required for the job.
Some examples of skills that might be required:
– Experience with Hadoop Distributed File System (HDFS)
– Experience with MapReduce programming paradigm
– Familiarity with Apache Hive and/or Apache Pig
Below is a list of common skills & terms:
- Apache Flume
- Apache HBase
- Apache Hadoop
- Apache Hive
- Apache Kafka
- Apache Mahout
- Apache Oozie
- Apache Spark
- Apache Sqoop
- Apache Storm
4. Education
Adding an education section to your resume is not mandatory, but if you choose to do so, focus on courses and subjects related to the Hadoop developer job you are applying for. For example, “Courses included Java programming, Big Data processing with Hadoop, and Data mining.”
If you don’t have a lot of work experience yet, or if your experience is not directly related to the job you want, including an education section can be helpful in demonstrating that you have the necessary skills and knowledge for the position.
Bachelor of Science in Computer Science
Educational Institution XYZ
Nov 2011
5. Certifications
Certifications can help you prove to potential employers that you have the skills required for the job. In some cases, certifications can also be used to satisfy requirements for certain positions.
If you have any relevant certifications, it is recommended that you include them in this section of your resume so that hiring managers can see them at a glance. Doing so will give you a significant advantage over other candidates who do not have such credentials.
Hadoop Developer Certification
Cloudera
May 2017
6. Contact Info
Your name should be the first thing a reader sees when viewing your resume, so ensure its positioning is prominent. Your phone number should be written in the most commonly used format in your country/city/state, and your email address should be professional.
You can also choose to include a link to your LinkedIn profile, personal website, or other online platforms relevant to your industry.
Finally, name your resume file appropriately to help hiring managers; for Eusebio Blick, this would be Eusebio-Blick-resume.pdf or Eusebio-Blick-resume.docx.
7. Cover Letter
A cover letter is a document that you include with your job application, typically after your resume. It’s an opportunity to introduce yourself and explain why you believe you’re the best candidate for the position.
Cover letters are not always required when applying for jobs, but they can give you a chance to stand out from other candidates. If you’re unsure whether or not to submit one, it’s always best to err on the side of caution and go ahead with including one.
Below is an example cover letter:
Dear Frances,
I am writing to apply for the Hadoop Developer position at XYZ Corporation. With eight years of experience in designing, developing, and managing large-scale Hadoop applications, I am confident that I can be an asset to your team.
In my previous role as a Hadoop Developer at ABC Corporation, I was responsible for designing and developing a new product that utilized Hadoop and MapReduce technologies. This product ended up being very successful, and it received positive feedback from both customers and management. In addition to this project, I have also developed several other successful applications using Hadoop and related technologies.
One of the things that sets me apart from other candidates is my ability to work with different teams in order to get the job done. For example, when working on the aforementioned project, I collaborated closely with the data team in order to ensure that the data was properly processed by our application. My skills in communication and collaboration would be a valuable asset to your organization.
I believe that my skills and experience make me an ideal candidate for this position, and I look forward to discussing how I can contribute to your team’s success. Thank you for your time and consideration; please do not hesitate to contact me if you have any questions or need clarification on anything in this letter or my attached resume
Sincerely,
[Your name]
Hadoop Developer Resume Templates
 Dugong
Dugong Quokka
Quokka Cormorant
Cormorant Bonobo
Bonobo Saola
Saola Echidna
Echidna Jerboa
Jerboa Axolotl
Axolotl Markhor
Markhor Rhea
Rhea Kinkajou
Kinkajou Indri
Indri Hoopoe
Hoopoe Lorikeet
Lorikeet Numbat
Numbat Gharial
Gharial Ocelot
Ocelot Fossa
Fossa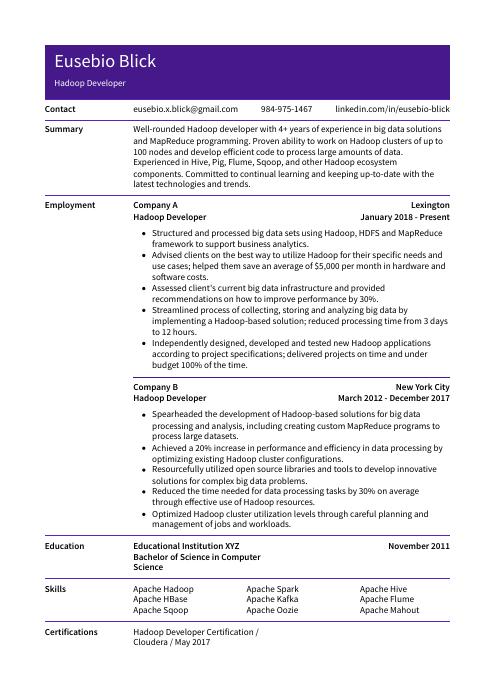 Pika
Pika